Before we discuss about Hadoop High Availability, we have to know what is high availability. Well high availability refers to a system or component that is continuously operational for a desirably long length of time. Availability can be approx to 100% operational or never failing.
So I will first tell you about HDFS High Availability and after that Yarn High Availability.
HDFS High Availability
To make the hdfs high available means it has to be available all the time. So we can achieve HDFS HA by making the namenode high available so that it could serve hdfs related requests and queries any time.
In hadoop versions 1 and 2 there are different approaches to achieve namenode high availability. In hadoop version 1.x, to achieve namenode high availability there was a primary Namenode and a Secondary Namenode. The secondary was there to take the back up of the hdfs metadata and also to take place of the primary Namenode in case the primary namenode failed. But there is a catch. The secondary namenode doesn’t automatically takes place of the primary namenode. We have to manually make the secondary namenode as an primary namenode. So that takes time and decreases productivity and during this period there is no namenode to take care of the hdfs related requests.
In Hadoop version 2.x there is a better approach that the previous one to achieve namenode high availability. In hadoop version 2.x there are two namenodes one of which is in active state and the other is in passive or standby state at any point of time. The active namenode serves all the requests while passive namenode watches the active namenode constantly and sync hdfs edits log files with it. Suppose if the active namenode goes down then the standby or passive namenode immediately becomes as an active namenode, reads all edits log files that it synced from the previous active namenode to make the namespace up to date and after that it continues serving all the client operations.
For fast failover it is necessary that the standby namenode have uptodate information regarding the location of blocks in the cluster. Therefore all the datanodes in the cluster are configured with the location of both namenodes. They send block location information and heartbeats to both namenodes at regular interval.
Well to prevent the data loss and incorrect results it is necessary that there must be one and only one active namenode at any point of time. There are some fencing method to achieve that property. I will cover in the upcoming slides.
Previously I told you that the passive namenode sync edits log files from the active namenode. So actually what happens is the active namenode writes edits log files to a place which is accessible to the passive namenode. That place is a shared directory or Journal nodes.
In case of shared directory both the namenodes have read and write access. Most of the times the share directory is an NFS which is mounted on both namenodes. The active namenode writes edits log file to shared directory and passive namenode constantly watches the shared directory and applies to itself. Thus, the availability of the system is limited by the availability of this shared edits directory, and therefore in order to remove all single points of failure there needs to be redundancy for the shared edits directory. Specifically, multiple network paths to the storage, and redundancy in the storage itself (disk, network, and power). Beacuse of this, it is recommended that the shared storage server be a high-quality dedicated NAS appliance rather than a simple Linux server.
In case Journal nodes, there are a group of multiple nodes in which active namenode writes edits log files, thus it removes the limitation of shared directory method. So in journal nodes, both namenodes communicate with a group of separate daemons called “JournalNodes” (JNs). When any namespace modification is performed by the Active node, it durably logs a record of the modification to a majority of these JNs. The Standby node is capable of reading the edits from the JNs, and is constantly watching them for changes to the edit log. As the Standby Node sees the edits, it applies them to its own namespace. In the event of a failover, the Standby will ensure that it has read all of the edits from the JounalNodes before promoting itself to the Active state. This ensures that the namespace state is fully synchronized before a failover occurs. The journal nodes allows only one namenode to write at a time to prevent data corruption.
The JournalNode daemon is relatively lightweight and there must be at least 3 JournalNode daemons, since edit log modifications must be written to a majority of JNs. This will allow the system to tolerate the failure of a single machine. You may also run more than 3 JournalNodes, but in order to actually increase the number of failures the system can tolerate, you should run an odd number of JNs, (i.e. 3, 5, 7, etc.). Note that when running with N JournalNodes, the system can tolerate at most (N – 1) / 2 failures and continue to function normally.
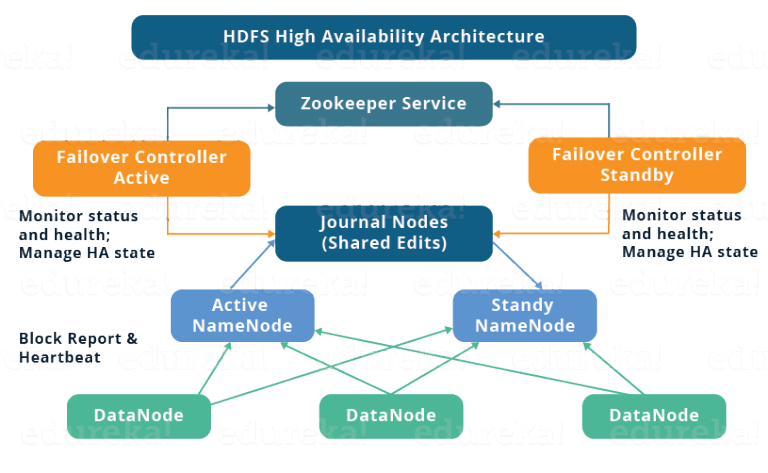
So here is the diagram of the architecture of HDFA HA Architecture. Before describing this diagram I want to give you a little information about zookeeper.
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. In short there are some nodes in which zookeeper is installed. Every node has information about the other zookeeper nodes. If you write some information on one node then it will automatically copy or sync the information to the other nodes so that you could retrieve your information from any node later. In this way if one zookeeper node goes down then you can still access your information from the remaining nodes. There are some limitations of Zookeeper like it writing speed is slow because it is designed as a high read, high throughput system for small keys. It is not designed as a large data store to hold very large data values.
Coming back to the diagram, so if you see this diagram from bottom to top, the datanodes are sending block reports and heartbeats both namenodes. Active namenode is writing edits log files to Journal Nodes and passive namenode is reading files from Journal node.
HDFA HA – Automatic Failover
Failover is a procedure to automatically transfer control to passive namenode in case of failure.
There are two types of failover – graceful failover and automatic failover. In graceful failover we have to manually initiate the failover for routine maintenance.
In case of automatic failover it is achieved with the help of zookeeper. In both the namenode there is client running called as Zookeeper Failover control in short ZkFC. The ZkFC process maintains a persistent session in ZooKeeper and also monitors the health of its namenode. The active namenode zkfc process holds a special lock with the zookeeper. If the active node goes down the zkfc tells the zookeeper and after that zkfc processes from all the namenode machines participate in an election to get the status of as an active namenode means becoming an active namenode.
HDFS HA Fencing Methods
In the previous slide I told you about ZkFC that how it monitors or elect a namenode as an active namenode and also told you that there have to only one active namenode at any point of time to prevent data corruption and only only namenode is allowed to write to the journal node. So there is possibility that after electing an active namenode the previous namenode suddenly become active and could serve read requests which may be out of date. So in this case a fencing method is required for the Journal nodes.
There are two types of fencing methods using which Journal nodes can prevent itself from serving multiple namenodes. One is SSH Fence method and another is Shell method.
In ssh fence method it ssh to the previous active namenode and kill the process. The sshfence option SSHes to the target node and uses fuser to kill the process listening on the service’s TCP port. In order for this fencing option to work, it must be able to SSH to the target node without providing a passphrase. Thus, one must also configure the property called dfs.ha.fencing.ssh.private-key-files, that is a comma-separated list of SSH private key files.
In the shell method we run an arbitrary shell command to fence the active namenode. You have to configure the property dfs.ha.fencing.methods and its value is the path of a shell script. If the shell command returns an exit code of 0, the fencing is determined to be successful. If it returns any other exit code, the fencing was not successful and the next fencing method in the list will be attempted.
HDFS HA Commands
So there are some hdfs ha commands. like getServiceState, checkHealth, failover, transitionToActive, transitionToStandby etc.
The getServiceState command determine whether the given NameNode is Active or Standby It connect to the provided NameNode to determine its current state, printing either “standby” or “active” to STDOUT appropriately. This subcommand might be used by cron jobs or monitoring scripts which need to behave differently based on whether the NameNode is currently Active or Standby.
The checkHealth command check the health of the given NameNode and It connect to the provided NameNode to check its health. The NameNode actually is capable of performing some diagnostics on itself, including checking if internal services are running as expected. This command will return 0 if the NameNode is healthy, non-zero otherwise. One might use this command for monitoring purposes.
The failover command initiate a failover between two NameNodes. This subcommand causes a failover from the first provided NameNode to the second. If the first NameNode is in the Standby state, this command simply transitions the second to the Active state without error. If the first NameNode is in the Active state, an attempt will be made to gracefully transition it to the Standby state. If this fails, the fencing methods (as configured by dfs.ha.fencing.methods) will be attempted in order until one succeeds. Only after this process will the second NameNode be transitioned to the Active state. If no fencing method succeeds, the second NameNode will not be transitioned to the Active state, and an error will be returned.
The transitionToActive and transitionToStandby commands transition the state of the given NameNode to Active or Standby. These subcommands cause a given NameNode to transition to the Active or Standby state, respectively. These commands do not attempt to perform any fencing, and thus should rarely be used. Instead, one should almost always prefer to use the “hdfs haadmin -failover” subcommand.
HDFS Federation
How the namenode Works ?
As far as we know that hdfs architecture is a master-slave architecture. The NameNode is the leader and the DataNodes are the followers. Before data is put or moved into HDFS it must first pass through the NameNode to be indexed. The DataNodes in HDFS store the data blocks, but they don’t know about the other DataNodes or data blocks. So if the NameNode goes down then their is not way to use data blocks without indexing.
HDFS not only stores the data, but provides the file system for users/clients to access the data inside HDFS. For example in my Hadoop environment I have Sales and Marketing data I want to logically separate. So I would, setup to different directories and populate sub directories in each depending on the data. Just like you have setup on your own work space environment. Pictures and Documents are in different directories or file folders. The key is that structure is stored as meta data and the NameNode in HDFS retains all that data.
But As data is accelerated into HDFS, the NameNode begins to grow out of it’s compute and storage. We can datanodes but we cannot scale namenode. So to solve this problem HDFS Federation was introduced.
Before understanding hdfs federation let me explain the current hdfs architecture.
In the current hdfs architecture there is one namespace and one blockstorage. The namespace manages directories, files and blocks. It supports file system operations such as creation, modification, deletion and listing of files and directories. Block storage has two parts block management and physical storage. Block Management maintains the membership of datanodes in the cluster. It supports block-related operations like creation, deletion, modification and getting location of the blocks and it also takes care of replica placement and replication. Physical Storage stores the blocks and provides read or write access to.
In the current architecture the namespace and block management are tightly coupled with each other and therefore restricts others from using block storage or datanodes directly and.. It also limits the number of blocks, files, and directories supported on the file system to what can be accommodated in the memory of a single namenode. Now lets come to the hdfs federation
In HDFS Federation architecture we can scale out the namenode horizontally by introducing multiple namenodes and all the namenodes are independent of each other. They has its own namespace and also don’t require coordination with each other. All the namenodes use datanodes commonly for block storage. Each Datanode registers with all the Namenodes in the cluster. Datanodes send periodic heartbeats and block reports. They also handle commands from the Namenodes.
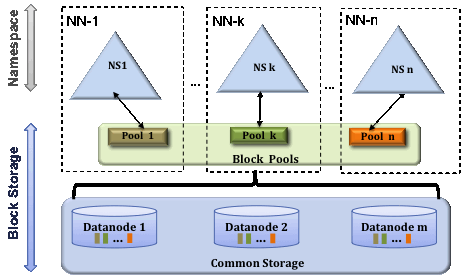
So lets see the hdfs federation architecture.
There are multiple namespaces (NS1, NS2,…, NSn) and each of them is managed by its respective NameNode. Each namespace has its own block pool ( NS1 has Pool 1, NSk has Pool k and so on ). As you can see in the diagram the blocks from pool 1 (sky blue) are stored on DataNode 1, DataNode 2 and so on. Similarly, all the blocks from each block pool will reside on all the DataNodes. A Block Pool actually is a set of blocks that belong to a single namespace. Datanodes store blocks for all the block pools in the cluster. Each Block Pool is managed independently. So it allows a namespace to generate Block IDs for new blocks without the need for coordination with the other namespaces. A Namenode failure does not prevent the Datanode from serving other Namenodes in the cluster. If a NameNode or namespace is deleted then the corresponding block pool which is residing on the DataNodes will also be deleted.
So this architecture has several benefits like Scalability, performance and isolation as I explained previously In federation File system throughput is not limited by a single Namenode. Adding more Namenodes to the cluster scales the file system read/write throughput. Taking about isolation well.. a single Namenode offers no isolation in a multi user environment. For example, an experimental application can overload the Namenode and slow down production critical applications. By using multiple Namenodes, different categories of applications and users can be isolated to different namespaces. Like there a separation namenode for devops and a separation namenode for production purpose. It also has design benefits like it is significantly simpler to design and implement. Namenodes and namespaces are independent of each other and require very little change to the existing namenodes. Federation also preserves backward compatibility of configuration.
Yarn HA
The purpose of yarn resource manager is scheduling applications and tracking of resources in the cluster. Before Hadoop 2.4 there was only single resource manager and it is the single point of failure. So in yarn ha feature removes this redundancy.
Yarn High availability is similar to HDFS High availability. Resource Manager HA is realized through an Active/Standby architecture – at any point of time, one of the RMs is Active, and one or more RMs are in Standby mode waiting to take over should anything happen to the Active. The trigger to transition-to-active comes from either the admin (through CLI) or through the integrated fail over-controller when automatic-fail over is enabled. When automatic failover is not enabled, admins have to manually transition one of the RMs to Active. To failover from one RM to the other, they are expected to first transition the Active-RM to Standby and transition a Standby-RM to Active. All this can be done using the “yarn rmadmin” CLI.
The RMs have an option to embed the Zookeeper-based ActiveStandbyElector to decide which RM should be the Active. When the Active goes down or becomes unresponsive, another RM is automatically elected to be the Active which then takes over. Note that, there is no need to run a separate ZKFC daemon as is the case for HDFS because ActiveStandbyElector embedded in RMs acts as a failure detector and a leader elector instead of a separate ZKFC deamon.
When there are multiple RMs, the configuration (yarn-site.xml) used by clients and nodes is expected to list all the RMs. Clients, ApplicationMasters (AMs) and NodeManagers (NMs) try connecting to the RMs in a round-robin fashion until they hit the Active RM. If the Active goes down, they resume the round-robin polling until they hit the “new” Active. This default retry logic is implemented as org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider. You can override the logic by implementing org.apache.hadoop.yarn.client.RMFailoverProxyProvider and setting the value of yarn.client.failover-proxy-provider to the class name.
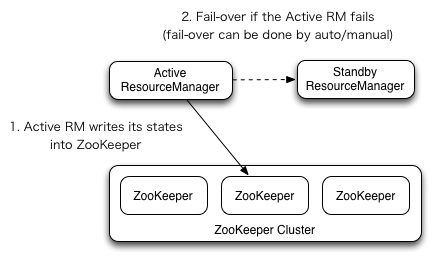
As you can see in the diagram there are two resource manager, one active and another is in standby mode. The active resource manager writing its current state to the zookeeper and in case of failure of active resource manager then standby resource manager will become active RM.
There are some commands for managin RM HA.
-getServiceState Returns the state of the service.
-checkHealth Requests that the service perform a health check. The RMAdmin tool will exit with a non-zero exit code if the check fails.
-failover [–forceactive] Initiate a failover from serviceId1 to serviceId2. Try to failover to the target service even if it is not ready if the –forceactive option is used. This command can not be used if automatic failover is enabled.
-transitionToActive [–forceactive] [–forcemanual] Transitions the service into Active state. Try to make the target active without checking that there is no active node if the –forceactive option is used. This command can not be used if automatic failover is enabled. Though you can override this by –forcemanual option, you need caution.
-transitionToStandby [–forcemanual] Transitions the service into Standby state. This command can not be used if automatic failover is enabled. Though you can override this by –forcemanual option, you need caution.
Leave a Reply